本地上訊數(shù)據(jù)網(wǎng)關(guān)現(xiàn)價
數(shù)據(jù)雷達提供了多種分類分級算法,包括AI大模型算法、正則算法、字典算法和應用算法,旨在滿足用戶不同的分類需求,提高數(shù)據(jù)分類的準確性和效率。AI大模型算法:(1)特征提取與模型訓練:用戶可根據(jù)業(yè)務(wù)需要新建AI算法名稱,并支持數(shù)據(jù)庫或文件兩種方式的特征提取,提取的算法特征用于訓練AI算法模型。(2)自動化分類分級:訓練完成后,系統(tǒng)自動切換至該算法模型,利用AI大模型實現(xiàn)自動化打標,降低人工干預和成本,提高工作效率。(3)支持多組特征數(shù)據(jù)操作:用戶可進行多組特征數(shù)據(jù)的追加和覆蓋操作,靈活應對不同的數(shù)據(jù)特征需求。借助上訊數(shù)據(jù)網(wǎng)關(guān) DG,企業(yè)可以實現(xiàn)對不同類型數(shù)據(jù)的管控,提升數(shù)據(jù)管理效率。本地上訊數(shù)據(jù)網(wǎng)關(guān)現(xiàn)價
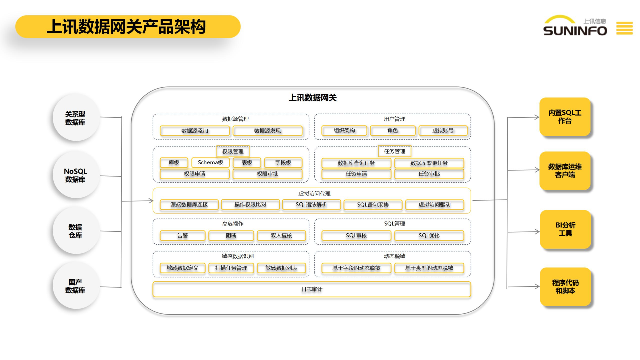
2018年的萬豪酒店事件。在這起事件中,黑客成功越過了酒店數(shù)據(jù)庫的安全防護,未經(jīng)授權(quán)地訪問了數(shù)據(jù)庫,導致超過3億客戶的個人信息被泄露。這些信息包括了客戶的姓名、聯(lián)系方式、信用卡信息等敏感數(shù)據(jù)。這一泄露事件引起了廣泛的關(guān)注和憤慨,不僅對萬豪酒店的聲譽造成了重大影響,也對客戶的隱私權(quán)產(chǎn)生了嚴重威脅,甚至可能引發(fā)法律訴訟。上海上訊信息技術(shù)股份有限公司自主研發(fā)的數(shù)據(jù)網(wǎng)關(guān)DG通過對數(shù)據(jù)庫操作人員的細顆粒度權(quán)限管控、敏感數(shù)據(jù)動態(tài)脫敏、SQL審核、高危操作管控等,實現(xiàn)運維過程中的事前預防、事中管控和事后審計,為數(shù)據(jù)庫管理者提供簡單高效的數(shù)據(jù)管控解決方案,滿足內(nèi)部數(shù)據(jù)安全保護需求和外部監(jiān)管要求。
跨源數(shù)據(jù)聯(lián)邦查詢和計算上訊數(shù)據(jù)網(wǎng)關(guān)實現(xiàn)運維過程中的事前預防、事中管控和事后審計。
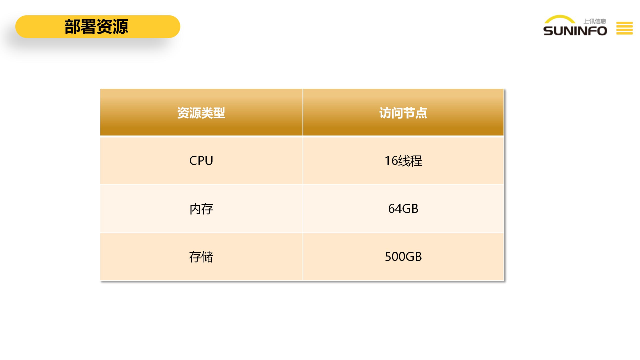
數(shù)據(jù)網(wǎng)關(guān)DG是數(shù)據(jù)庫管理的**工具,具有一些功能特點,以強化權(quán)限管理,確保數(shù)據(jù)的安全性和可控性。審批流程的靈活性:數(shù)據(jù)網(wǎng)關(guān)DG引入工單模式,實現(xiàn)完備的審批、申請流程,包括被動式審批授權(quán)和主動式申請授權(quán),并支持對提交的申請進行同意、駁回等操作,確保審批流程能夠高效運轉(zhuǎn)。操作員可以配置數(shù)據(jù)庫訪問時間(如*在工作日下午17:00-18:00訪問),并限制外部應用訪問權(quán)限。字段級別權(quán)限劃分:數(shù)據(jù)網(wǎng)關(guān)DG支持對數(shù)據(jù)訪問權(quán)限進行字段級別的劃分,通過增、刪、改、查等權(quán)限,對數(shù)據(jù)訪問者進行細顆粒度的權(quán)限管控,遵循**小權(quán)限原則,確保數(shù)據(jù)訪問者只能訪問自身權(quán)限的數(shù)據(jù)源。
數(shù)據(jù)雷達DR基于AI大模型進行分類分級:在實現(xiàn)數(shù)據(jù)分類分級的過程中,語義級別的數(shù)據(jù)分類分級引擎采用了基于AI大模型的先進技術(shù)。這一引擎能夠同時對數(shù)據(jù)類型進行詞法、語法和語義級別的特征提取和分析,從而建立起語義級別的高維度特征向量。通過這種方式,引擎能夠更加準確地理解和區(qū)分不同類型的數(shù)據(jù),提高了數(shù)據(jù)分類分級的精確度和可信度。基于數(shù)據(jù)字段內(nèi)容的模型訓練,保證了數(shù)據(jù)分類分級模型的可復制性:語義級別的數(shù)據(jù)分類分級引擎注重保證數(shù)據(jù)分類分級模型的可復制性,采用AI大模型進行訓練時,引擎不依賴于數(shù)據(jù)字段的名稱和注釋,即使在沒有明確的字段描述情況下也能夠達到很高的準確度。這意味著訓練后的數(shù)據(jù)分類分級模型在不同的數(shù)據(jù)環(huán)境下都能夠穩(wěn)定可靠地運行,具有很高的適用性和通用性,為數(shù)據(jù)管理和安全保障提供可靠的支持和保障。 數(shù)據(jù)網(wǎng)關(guān)DG支持高可用部署,確保系統(tǒng)在高負載和異常情況下依然保持穩(wěn)定運行。
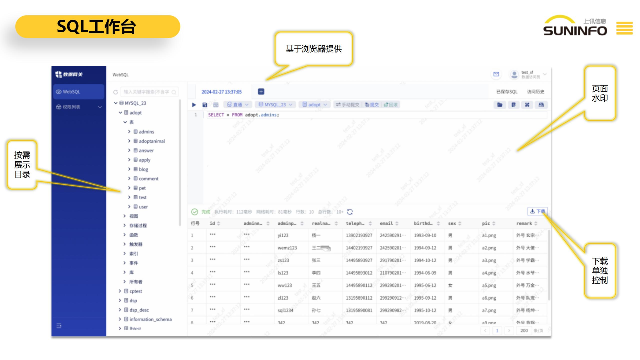
大多企業(yè)數(shù)據(jù)環(huán)境中存在著多樣化的數(shù)據(jù)庫類型和數(shù)據(jù)存儲平臺。為了有效管理這些數(shù)據(jù)庫,數(shù)據(jù)雷達DR提供了***的數(shù)據(jù)庫管理功能,涵蓋了以下關(guān)鍵方面:***的數(shù)據(jù)庫類型支持:支持不低于40種數(shù)據(jù)庫類型,包括常見的主流數(shù)據(jù)庫(如Oracle、MySQL、SQLServer、DB2、PostgreSQL等)、國產(chǎn)數(shù)據(jù)庫(如DM、GaussDB、Oscar等)以及大數(shù)據(jù)平臺下的數(shù)據(jù)庫(如Elasticsearch、MongoDB、Hbase等)。平臺通過支持常見的jdbc協(xié)議,實現(xiàn)對各種數(shù)據(jù)庫的連接和管理。為提高操作效率,數(shù)據(jù)網(wǎng)關(guān)DG支持根據(jù)模板批量導入脫敏策略,簡化大量配置脫敏策略的流程。哪個上訊數(shù)據(jù)網(wǎng)關(guān)哪個好
數(shù)據(jù)網(wǎng)關(guān)DG提供直觀易用的定時執(zhí)行任務(wù)的設(shè)置,以確保定期對敏感數(shù)據(jù)進行識別,降低潛在風險。本地上訊數(shù)據(jù)網(wǎng)關(guān)現(xiàn)價
數(shù)據(jù)雷達提供了多種分類分級算法,包括AI大模型算法、正則算法、字典算法和應用算法,旨在滿足用戶不同的分類需求,提高數(shù)據(jù)分類的準確性和效率。自定義算法分組:通過自定義算法分組,用戶可以根據(jù)算法的功能、用途或者行業(yè)領(lǐng)域等因素進行分類,將具有相似特性或者功能的算法歸類到同一個分組下。這樣一來,用戶可以更快速地找到需要的算法,同時也可以更清晰地了解系統(tǒng)中各個算法的分類和屬性。分類分級算法共享:所有用戶均可在分類分級算法組織架構(gòu)下共享這些算法,提升了協(xié)作效率和資源利用率。數(shù)據(jù)分類分級算法能夠為企業(yè)提供高效、準確的數(shù)據(jù)分類和分級服務(wù),幫助企業(yè)更好地管理和保護數(shù)據(jù)資產(chǎn),降低數(shù)據(jù)泄露和濫用的風險,提升數(shù)據(jù)安全性和合規(guī)性水平,增強企業(yè)對數(shù)據(jù)的控制能力,從而提升企業(yè)的運營效率和競爭力。本地上訊數(shù)據(jù)網(wǎng)關(guān)現(xiàn)價
- SSH告警 2025-06-09
- 信息架構(gòu) 2025-06-09
- 人工智能科技 2025-06-09
- 業(yè)務(wù)流程 2025-06-09
- 資產(chǎn)訪問 2025-06-09
- IP臺賬 2025-06-09
- IT資產(chǎn)清單 2025-06-09
- IAM集成 2025-06-09
- 原生網(wǎng)絡(luò)監(jiān)控 2025-06-09
- 認證報告 2025-06-09
- 洪山區(qū)市場企業(yè)管理咨詢服務(wù)電話 2025-06-16
- 蘇州什么公司可編程邏輯控制器比較可靠 2025-06-16
- 奉賢區(qū)標準活動策劃信息中心 2025-06-16
- 金山區(qū)企業(yè)管理咨詢商家 2025-06-16
- 廣州琶洲(廣交會展館)巖板會議論壇 2025-06-16
- 潮州驗廠項目都有哪些 2025-06-16
- 四平哪家公司實木家具靠譜 2025-06-16
- 廣東巖板技術(shù)與產(chǎn)品展 2025-06-16
- 2025年6月18-21日華南國際拋光磚展覽會 2025-06-16
- 山東機動車產(chǎn)品質(zhì)量鑒定 2025-06-16